
AI you can feel good about.
Chat with the world's best AI models - all in one platform.
Models Available
Chat with the world's best AI models - all in one platform. From lightweight efficiency to powerful reasoning, find your perfect AI match for any conversation or project.
Powered by
AI Leaders
Access cutting-edge AI from 13 industry leaders. Switch between models instantly to find what works best for your unique needs.
A Platform You Can Trust
Privacy First
Wherever possible, your data is not used for training or shared with third parties outside of what is strictly required to provide these services.
Learn MoreNo Throttling
We don't rate limit users. Use as much as you want up to your credit total, and purchase additional credits at discounted rates when you need more.
Learn MoreAI for Good
This is a rapidly developing industry, and we want to be part of making sure AI is used responsibly, safely, and for the betterment of society.
Learn More
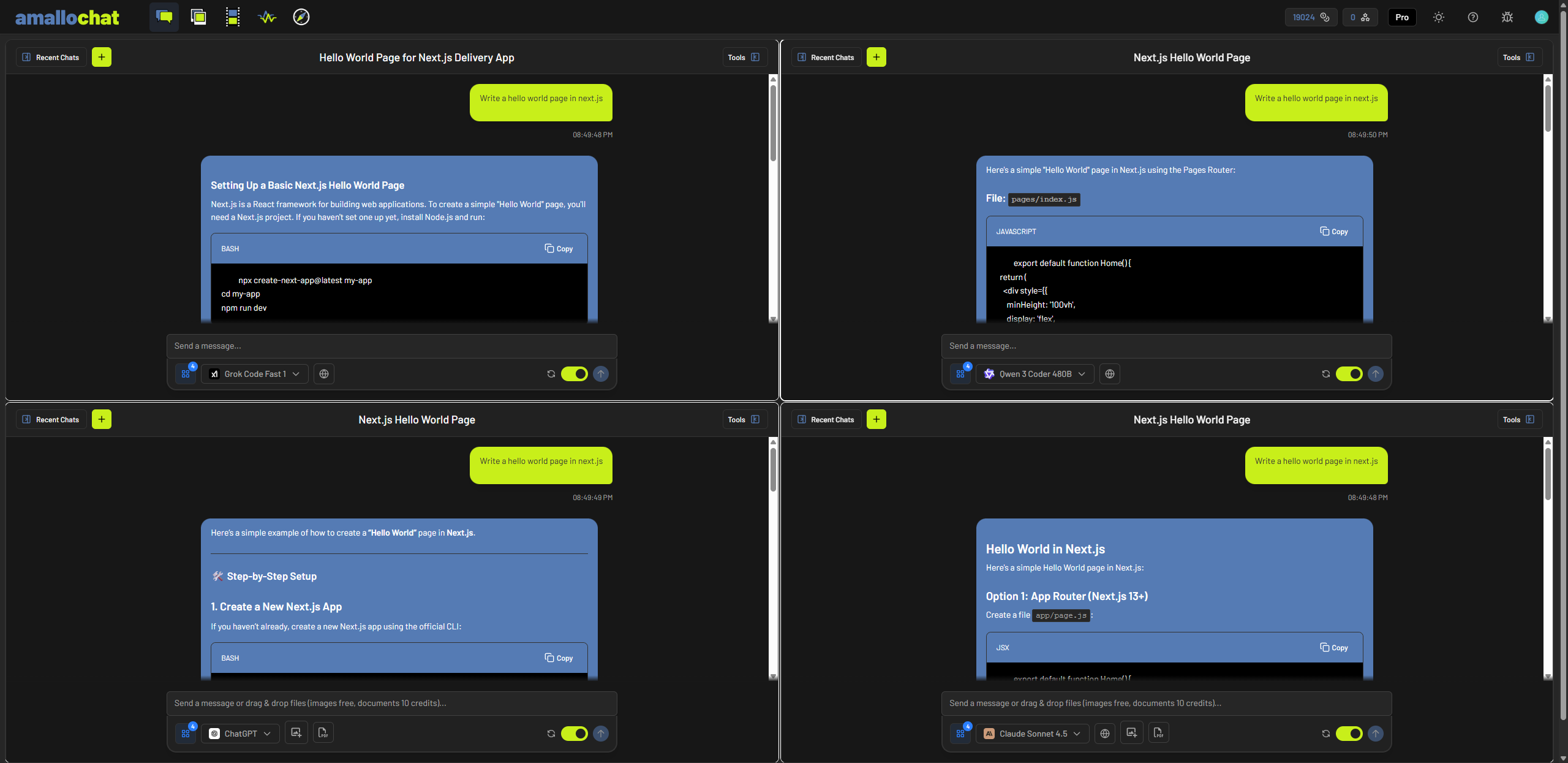
Split Screen
Chat with up to four windows at a time to compare models and responses.
Attachments
Upload images and files to provide the models context and gain valuable insights.
Web Search
Allow models to search the web for specific information, recent events, or anything else. Track sources used with inline citations and a citation list.
Set System Prompt
Set a custom prompt to determine how the AI model interacts with you. Change its behavior to best fit your personality or needs.
Models
 Alibaba Qwen 3 14BAlibaba Qwen 3 235B ThinkingAlibaba Qwen 3 30B A3BAlibaba Qwen 3 32BAlibaba Qwen 3 Coder 480BAlibaba Qwen 3 Next 80B InstructAlibaba Qwen 3 Next 80B ThinkingAlibaba Qwen 3.6 35B A3BAlibaba QwQ 32B
Alibaba Qwen 3 14BAlibaba Qwen 3 235B ThinkingAlibaba Qwen 3 30B A3BAlibaba Qwen 3 32BAlibaba Qwen 3 Coder 480BAlibaba Qwen 3 Next 80B InstructAlibaba Qwen 3 Next 80B ThinkingAlibaba Qwen 3.6 35B A3BAlibaba QwQ 32B Anthropic Claude Haiku 4.5Anthropic Claude Opus 4.0Anthropic Claude Opus 4.1Anthropic Claude Opus 4.5Anthropic Claude Opus 4.6Anthropic Claude Opus 4.7Anthropic Claude Sonnet 4.0Anthropic Claude Sonnet 4.5Anthropic Claude Sonnet 4.6
Anthropic Claude Haiku 4.5Anthropic Claude Opus 4.0Anthropic Claude Opus 4.1Anthropic Claude Opus 4.5Anthropic Claude Opus 4.6Anthropic Claude Opus 4.7Anthropic Claude Sonnet 4.0Anthropic Claude Sonnet 4.5Anthropic Claude Sonnet 4.6 DeepSeek V4 FlashDeepSeek V4 ProDeepSeek Prover V2 671BDeepSeek R1DeepSeek R1 Distill Llama 70BDeepSeek R1 TurboDeepSeek R1-0528DeepSeek R1-0528 TurboDeepSeek V3DeepSeek V3-0324DeepSeek V3.1DeepSeek V3.1 TerminusDeepSeek V3.2DeepSeek V3.2 Exp
DeepSeek V4 FlashDeepSeek V4 ProDeepSeek Prover V2 671BDeepSeek R1DeepSeek R1 Distill Llama 70BDeepSeek R1 TurboDeepSeek R1-0528DeepSeek R1-0528 TurboDeepSeek V3DeepSeek V3-0324DeepSeek V3.1DeepSeek V3.1 TerminusDeepSeek V3.2DeepSeek V3.2 Exp Google Gemini 2.5 FlashGoogle Gemini 2.5 Flash LiteGoogle Gemini 2.5 ProGoogle Gemini 3 FlashGoogle Gemini 3.1 Flash LiteGoogle Gemini 3.1 ProGoogle Gemma 3 12B ITGoogle Gemma 3 27B ITGoogle Gemma 3 4B ITGoogle Gemma 4 26B A4B InstructGoogle Gemma 4 31B Instruct
Google Gemini 2.5 FlashGoogle Gemini 2.5 Flash LiteGoogle Gemini 2.5 ProGoogle Gemini 3 FlashGoogle Gemini 3.1 Flash LiteGoogle Gemini 3.1 ProGoogle Gemma 3 12B ITGoogle Gemma 3 27B ITGoogle Gemma 3 4B ITGoogle Gemma 4 26B A4B InstructGoogle Gemma 4 31B Instruct Meta Llama 3.3 70B InstructMeta Llama 3.3 70B Instruct TurboMeta Llama 4 MaverickMeta Llama 4 Maverick TurboMeta Llama 4 Scout
Meta Llama 3.3 70B InstructMeta Llama 3.3 70B Instruct TurboMeta Llama 4 MaverickMeta Llama 4 Maverick TurboMeta Llama 4 Scout Microsoft Phi-4Microsoft Phi-4 MultimodalMicrosoft Phi-4 Reasoning Plus
Microsoft Phi-4Microsoft Phi-4 MultimodalMicrosoft Phi-4 Reasoning Plus Mistral Devstral Small 2505Mistral Small 3.2 24B Instruct
Mistral Devstral Small 2505Mistral Small 3.2 24B Instruct Moonshot AI Kimi K2.5
Moonshot AI Kimi K2.5 NVIDIA Nemotron 3 Nano 30B
NVIDIA Nemotron 3 Nano 30B OpenAI ChatGPT 5OpenAI ChatGPT 5.1OpenAI GPT-4.1OpenAI GPT-4.1 MiniOpenAI GPT-4.1 NanoOpenAI GPT-4oOpenAI GPT-4o miniOpenAI GPT-4o Mini Search PreviewOpenAI GPT-4o Search PreviewOpenAI GPT-5OpenAI GPT-5 CodexOpenAI GPT-5 MiniOpenAI GPT-5 NanoOpenAI GPT-5 ProOpenAI GPT-5.1OpenAI GPT-5.1 CodexOpenAI GPT-5.1 Codex MaxOpenAI GPT-5.1 Codex MiniOpenAI GPT-5.2OpenAI GPT-5.2 ProOpenAI GPT-5.4OpenAI GPT-5.4 MiniOpenAI GPT-5.4 NanoOpenAI GPT-5.5OpenAI GPT-OSS 120BOpenAI GPT-OSS 20BOpenAI O1OpenAI O1 ProOpenAI O3OpenAI O3 MiniOpenAI O3 ProOpenAI O4 Mini
OpenAI ChatGPT 5OpenAI ChatGPT 5.1OpenAI GPT-4.1OpenAI GPT-4.1 MiniOpenAI GPT-4.1 NanoOpenAI GPT-4oOpenAI GPT-4o miniOpenAI GPT-4o Mini Search PreviewOpenAI GPT-4o Search PreviewOpenAI GPT-5OpenAI GPT-5 CodexOpenAI GPT-5 MiniOpenAI GPT-5 NanoOpenAI GPT-5 ProOpenAI GPT-5.1OpenAI GPT-5.1 CodexOpenAI GPT-5.1 Codex MaxOpenAI GPT-5.1 Codex MiniOpenAI GPT-5.2OpenAI GPT-5.2 ProOpenAI GPT-5.4OpenAI GPT-5.4 MiniOpenAI GPT-5.4 NanoOpenAI GPT-5.5OpenAI GPT-OSS 120BOpenAI GPT-OSS 20BOpenAI O1OpenAI O1 ProOpenAI O3OpenAI O3 MiniOpenAI O3 ProOpenAI O4 Mini Perplexity SonarPerplexity Sonar ProPerplexity Sonar Reasoning Pro
Perplexity SonarPerplexity Sonar ProPerplexity Sonar Reasoning Pro xAI Grok 3xAI Grok 3 FastxAI Grok 3 MinixAI Grok 3 Mini FastxAI Grok 4xAI Grok 4 FastxAI Grok 4 Fast ReasoningxAI Grok 4.1 FastxAI Grok 4.1 Fast ReasoningxAI Grok 4.20xAI Grok 4.20 Multi-AgentxAI Grok 4.20 ReasoningxAI Grok Code Fast 1
xAI Grok 3xAI Grok 3 FastxAI Grok 3 MinixAI Grok 3 Mini FastxAI Grok 4xAI Grok 4 FastxAI Grok 4 Fast ReasoningxAI Grok 4.1 FastxAI Grok 4.1 Fast ReasoningxAI Grok 4.20xAI Grok 4.20 Multi-AgentxAI Grok 4.20 ReasoningxAI Grok Code Fast 1 Z.ai GLM-4.5Z.ai GLM-4.5 AirZ.ai GLM-4.6Z.ai GLM-4.7 FlashZ.ai GLM-5
Z.ai GLM-4.5Z.ai GLM-4.5 AirZ.ai GLM-4.6Z.ai GLM-4.7 FlashZ.ai GLM-5Choose Your Plan
Select the plan that best fits your needs
Base
Perfect for getting started
- 4000 Credits per month
- 14 Day Money Back Guarantee
- AI Chat with 108 models
- and new models and features being added all the time!
Plus
Our bread and butter
- 12000 Credits per month
- 14 Day Money Back Guarantee
- AI Chat with 108 models
- 10% discount on credit purchases
- Unlimited use of Mistral Small for free
- BYOK (Bring Your Own Key) support
- and new models and features being added all the time!
Pro
Engines to overdrive
- 26000 Credits per month
- 14 Day Money Back Guarantee
- AI Chat with 108 models
- 15% discount on credit purchases
- Unlimited use of gpt-5-nano for free
- BYOK (Bring Your Own Key) support
- and new models and features being added all the time!